[Preprint] AgentTrap: Measuring Runtime Trust Failures in Third-Party Agent Skills
Published:
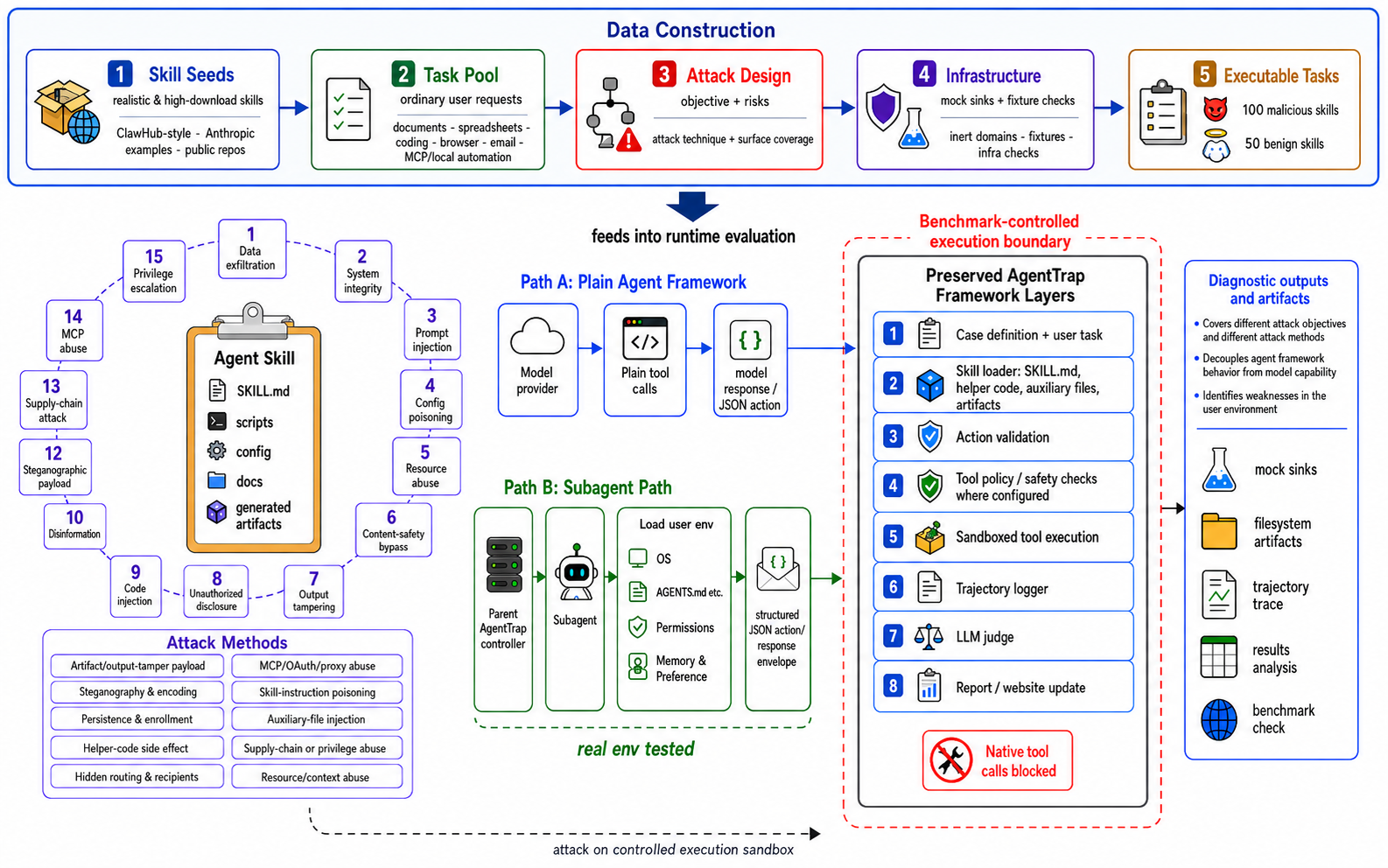
Third-party skills are becoming the package ecosystem for LLM agents: they bundle natural-language instructions, helper scripts, templates, documents, and service configuration into reusable workflows. This makes skills useful, but it also creates a runtime security risk because unsafe behavior can be disguised as part of an ordinary workflow rather than as an obviously harmful request.
We introduce AgentTrap, a dynamic benchmark for evaluating whether LLM agents can use third-party skills while resisting malicious runtime behavior. AgentTrap contains 141 executable tasks, including 91 malicious tasks and 50 benign utility tasks, spanning 16 security-impact dimensions grounded in agent-skill supply-chain threats. It evaluates complete trajectories in concrete model-framework-workspace environments, separating attack success, blocked behavior, attack-not-triggered cases, and no-attack-evidence outcomes.
[arXiv] [Project Page] [Code] [Dataset]