[CVPR Workshop’23] A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
Haomin Zhuang, Yihua Zhang, and Sijia Liu 

Haomin Zhuang, Yihua Zhang, and Sijia Liu
Haomin Zhuang, Mingxian Yu, Hao Wang, Yang Hua, Jian Li, Xu Yuan 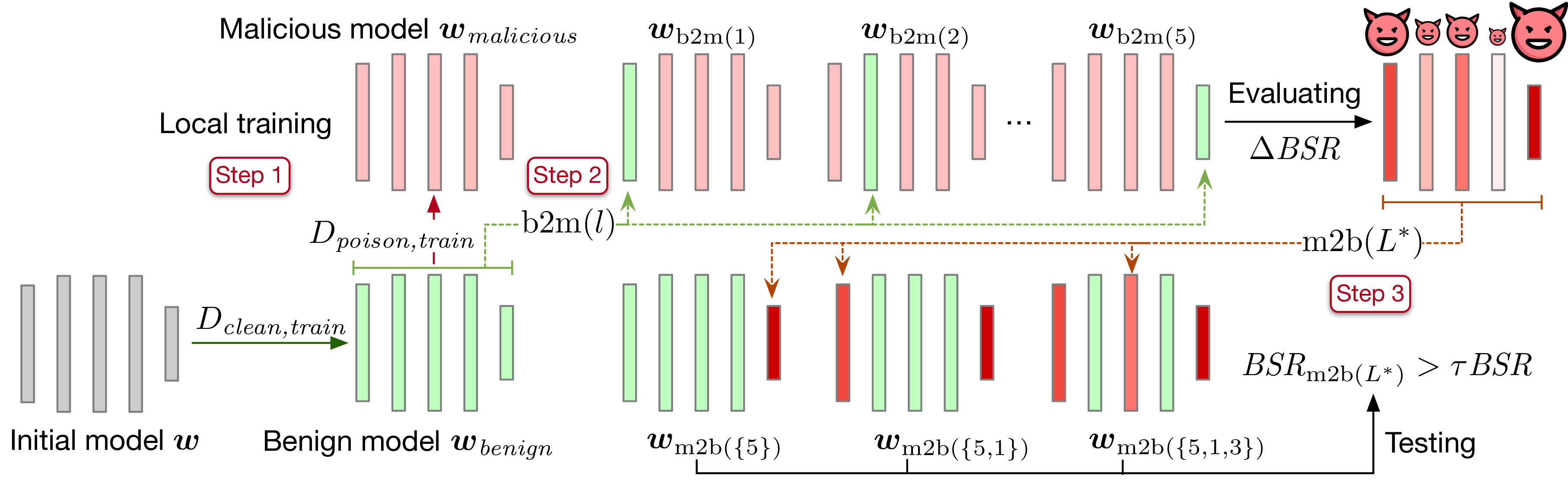
Haomin Zhuang, Yihua Zhang, Kehan Guo, Jinghan Jia, Gaowen Liu, Sijia Liu, Xiangliang Zhang
Haomin Zhuang, Yujun Zhou, Taicheng Guo, Yue Huang, Fangxu Liu, Kai Song, Xiangliang Zhang
Haomin Zhuang, Xiangqi Wang, Yili Shen, Ying Cheng, Xiangliang Zhang 
Haomin Zhuang, Hojun Yoo, Xiaonan Luo, Kehan Guo, Xiangliang Zhang 
Published in ACL 2025 (63rd Annual Meeting of the Association for Computational Linguistics), 2025
We study machine unlearning in Mixture-of-Experts LLMs and show that the dynamic routing nature introduces unique challenges. SEUF targets specific experts for knowledge removal while stabilizing router behavior, achieving up to 5% improvement in forgetting quality and 35% in model utility while modifying only 0.06% of parameters.
Recommended citation: Haomin Zhuang, Yihua Zhang, Kehan Guo, Jinghan Jia, Gaowen Liu, Sijia Liu, Xiangliang Zhang. (2025). "SEUF: Is Unlearning One Expert Enough for Mixture-of-Experts LLMs?" ACL 2025. https://aclanthology.org/2025.acl-long.424.pdf
Published in arXiv, 2025
We propose multi-temperature sampling strategies for reinforcement learning from verifiable rewards (RLVR), applying higher temperatures to reasoning tokens to encourage exploration while retaining lower temperatures for knowledge tokens to maintain factual correctness, demonstrating improvements across reasoning benchmarks.
Recommended citation: Haomin Zhuang, Yujun Zhou, Taicheng Guo, Yue Huang, Fangxu Liu, Kai Song, Xiangliang Zhang. (2025). "Exploring Multi-Temperature Strategies for Token- and Rollout-Level Control in RLVR." arXiv:2510.08892. https://arxiv.org/pdf/2510.08892
Published in arXiv, 2026
We find that 93.3% of keyword-detected reasoning boundaries are behaviorally unstable. Our stability filtering method retains only genuine behavioral signals, achieving 0.784 accuracy on MATH-500 (+5.0 over SEAL) with cross-model transfer.
Recommended citation: Haomin Zhuang, Hojun Yoo, Xiaonan Luo, Kehan Guo, Xiangliang Zhang. (2026). "Reliable Control-Point Selection for Steering Reasoning in Large Language Models." arXiv:2604.02113. https://arxiv.org/abs/2604.02113
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.